Quelles sont les limites de la conteneurisation ?
Dans le monde de la recherche, la conteneurisation avec Kubernetes, Apptainer ou Docker a été massivement investie [¹] pour mettre à disposition des images du code source réutilisables sur des ordinateurs très différents de ceux qui ont été utilisés pour concevoir le code.
Par exemple, le conteneur permet de reproduire sur une machine où l’on ne dispose que de Windows comme système d’exploitation un code source qui a été conçu avec une machine sur laquelle fonctionne une distribution GNU/Linux.
Le succès de cette technique de la conteneurisation est indéniable mais elle reste néanmoins limitée dans ses effets. Nous allons voir pourquoi, et dans un second temps, nous verrons comment ces limites, au moins certaines d’entre elles, peuvent être levées.
Pour ce qui suit, nous nous basons sur deux études récentes qui manifestent la dégradation avec le temps du taux de reproduction des artefacts générés par le code source à l’identique (ici la notion de reproduction à l’identique peut varier selon qu’on parle de reproductibilité bit à bit ou de reproductions plus faciles à obtenir : même résultats avec les mêmes packages par exemple).
La première étude de Julien MALKA, Stefano ZACCHIROLI et Théo ZIMMERMANN, a été déposée sur ArXiv.org en janvier 2026. Elle procède par différentes étapes pour manifester les limites de la conteneurisation avec Docker. La première étape consiste à mener une revue systématique des articles qui parlent de ce que la communauté scientifique peut attendre en termes de reproductibilité de l’usage de Docker et réaliser une analyse quantitative des bonnes pratiques qui sont échangées dans ces articles pour garantir cette reproductibilité, particulièrement dans la conception du Dockerfile. Puis les auteurs tentent de reproduire plus de 5000 images Docker présents en 2023 dans autant de dépôts sur Github (et générés au moyen de github actions), afin de mesurer le taux de reproductibilité deux ans plus tard. Ils mènent une analyse des dockerfiles en lien avec les différents niveaux de succès ou d’échecs en matière de reproductibilité pour déterminer si les bonnes pratiques échangées dans la littérature scientifique sont bien celles qu’il faut suivre pour maintenir un code source reproductible au moyen de Docker.
La seconde étude de Quentin GUILLOTEAU Antoine WAEHREN et Florina M. CIORBA opte pour une approche centrée sur 5 projets scientifiques fournis sous la forme d’images Docker. Les auteurs se proposent de mesurer la variabilité dans le temps des différentes images, notamment en mesurant la quantité de nouvelles versions des paquets appelés par le code source qui sont intégrés au fur et à mesure du fait d’un problème de conception dans le Dockerfile ou bien de la nature même des gestionnaires de paquets qui ne peuvent garantir la récupération des paquets à l’identique.
Il n’est pas possible d’auditer autant que nécessaire une image Docker
Une image Docker en soi est quelque chose de difficile à analyser.
un conteneur c’est comme un smoothie. Un smoothie est un jus dans lequel on a mixé plein de fruits différents mais qu’on a du mal à distinguer dans le produit final ou bien dont il est difficile de mesurer la quantité dans le verre, ce pourquoi on aura du mal à refaire le smoothie à l’identique
📓1
C’est pourquoi à des fins de transparence, mais aussi d’économie de place, une bonne pratique souvent lue dans les publications sur Docker est de partager le Dockerfile à côté ou à la place de l’image.
Mais que ce soit l’image ou bien le Dockerfile, ces deux artefacts sont difficiles à reproduire sur le temps long (à l’échelle de plusieurs mois), surtout à reproduire à l’identique (même environnement avec les mêmes paquets = mêmes résultats). Dans l’empan d’un seul mois après la soumission d’un article avec son code source, les reviewers peuvent constater des variations en reproduisant l’image à partir du Dockerfile 📓2
Pour Malka et al. il vaut mieux ne partager que le Dockerfile plutôt que l’image qui en fonction d’un environnement computationnel variable risque d’être reconstruite de façon différente par rapport à la version historique sans qu’on puisse avoir accès aux paramètres qui causent cette variation (on peut en revanche adapter le Dockerfile).
Les images Docker posent des problèmes de sécurité
Les images Docker que les chercheurs et chercheuses téléchargent depuis des serveurs comme Dockerhub ne peuvent pas être reproduites bit à bit. Par conséquent elles sont livrées sans signature cryptographique. Ainsi, il n’y a aucun moyen d’être sûr qu’entre le concepteur de l’image et la personne qui la réutilise une personne mal intentionnée n’a pas rajouté un bout de code malveillant. Ce problème est crucial alors que les infrastructures scientifiques sont en permanence ciblées par des opérations d’extorsion de données 📓2.
Les Dockerfile ne présisent pas suffisamment les versions des packages utilisés
Les auteurs de ces deux études constatent une grande variabilité dans les packages installés lorsque les images sont reproduites. En effet, les Dockerfiles ne pointent pas suffisamment les versions des packages qui permettent la reconstitution de l’image Docker. Cette imprécision est parfois recherchée comme un moyen de tenir le code source à jour. Des utilisateurs ou utilisatrices peuvent considérer qu’en permettant le chargement des dernières versions des paquets, la durée de vie de l’image (au sens où elle pourra être reconstruite et/ou exécutée avec succès) sera plus longue, en tout cas demandera moins de maintenance. C’est pourquoi, certaines personnes chargent les dernières versions des images de base disponibles (FROM Ubuntu:latest par exemple) ou bien mettent à jour le registre des paquets disponibles (RUN apt-get update). Cela facilite peut-être l’exécution du code source dans le temps, mais cela nuit à la reproductibilité des résultats. En effet, par rapport à l’exécution d’origine du code source, de nouvelles versions des packages auront été chargées qui sont susceptibles d’apporter des variations plus ou moins grandes aux résultats obtenus. Si dans l’industrie, la possibilité de réutiliser une image est primordiale, dans la science, il faut pouvoir réutiliser cette image autant que possible à l’identique.
L’étude de Guilloteau et al. manifeste comment de nouvelles versions des packages mentionnés dans le Dockerfile s’invitent au fil des mois 📓3
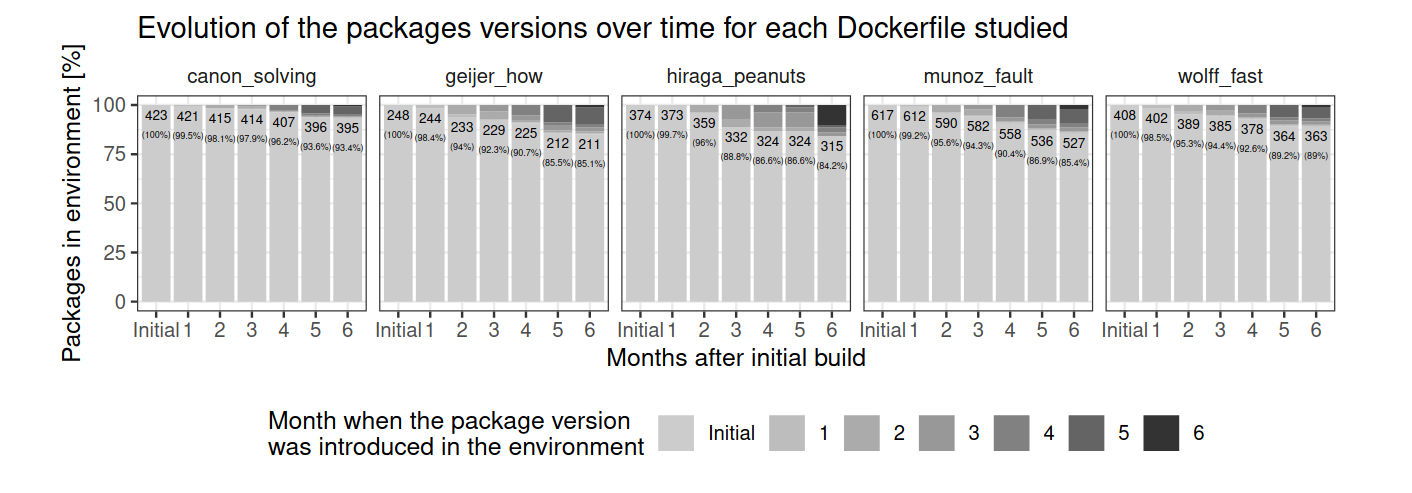 D’après cette même étude, si on constate une certaine stabilité des packages téléchargées depuis Git, pip, le gestionnaire de paquets pour Python est la source qui enregistre la plus forte évolution de ses paquets et pour laquelle l’introduction de nouvelles versions dans le code compilé est la plus manifeste. Une bonne pratique consiste donc à remplacer dans le Dockerfile
D’après cette même étude, si on constate une certaine stabilité des packages téléchargées depuis Git, pip, le gestionnaire de paquets pour Python est la source qui enregistre la plus forte évolution de ses paquets et pour laquelle l’introduction de nouvelles versions dans le code compilé est la plus manifeste. Une bonne pratique consiste donc à remplacer dans le Dockerfile pip install folium par pip install folium==0.19.40 --force-reinstall si c’est à la base la version 0.19.4 de folium qu’on a utilisée. (l’argument –force-reinstall permet de réécrire cette librairie si une autre version est fournie dans l’image de base).
Docker ne gère pas l’accessibilité des packages sur le temps long
Si les images de base officielles restent accessibles assez longtemps, ce n’est pas le cas des images dites “privées” (private base images), que tout à chacun peut se constituer pour coller à ses propres besoins. Une bonne pratique, pas toujours bien suivie, consiste donc à ne pas utiliser d’autres images que celles du dépôt officiel de Docker et à utiliser les lignes suivantes du Dockerfile pour ajouter les dépendances système manquantes 📓2.
[¹]: Kubernétès permet de dockeriser plusieurs logiciels en même temps. Pour des études spécifiques, Docker est davantage utilisé car plus abordable à un.e chercheur.se qui n’est pas informaticien.ne. Une étude de 2020 a montré en faisant un sondage dans l’archive “World of Code” que plus d’1,9 millions de dépôts réalisés contenaient un dockerfile. 📓2